问题出现:现网CPU飙高,Full GC告警
CGI 服务发布到现网后,现网机器出现了Full GC告警,同时CPU飙高99%。在优先恢复现网服务正常后,开始着手定位Full GC的问题。在现场只能够抓到四个GC线程占用了很高的CPU,无法抓到引发Full GC的线程。查看了服务故障期间的错误日志,发现更多的是由于Full GC引起的问题服务异常日志,无法确定Full GC的根源。为了查找问题的根源,只能从发布本身入手去查问题,发现一次bugfix的提交,有可能触发一个死循环逻辑:
for(int i = 1 ;i <= totalPage ;i++) { String path = path_prefix + "?cmd=txt_preview&page=" + String.valueOf(i) + "&sign=" + fileSignature; url_list.add(path);} 循环中的参数totalPage为long类型,由一个外部参数进行赋值。当外部参数非常大,超过int的最大值时,i递增到int的最大值后,i++会发生翻转,变成一个负数,从而使for会进入死循环。利用下面这段代码可以试验:
public static void main(String[] args) { long totalPage = Long.MAX_VALUE; for(int i = 0 ;i 通过日志,发现外部确实传递了一个非常大的参数:

确认了当命中逻辑的时候,会进入一个死循环。在循环中不断进行字符串的拼接与list的Add操作,很快就会耗尽JVM堆内存导致Full GC。经过测算,实际上并不需要死循环,只要是一个比较大的循环,就能够引发Full GC。对totlePage的大小做了限定后,发布了新版本,没有再出现Full GC的问题。
现场还原:重现问题,探索定位思路
回顾排查问题的过程并不高效,最开始怀疑过是否是打包有问题或使用的jdk版本不对,花了较多的时间确认打包问题。另一方面,发布带出的代码较多,通过重复review代码无法很快锁定问题。为了探索一种更有效的问题定位方法,我将有问题的代码重新部署到机器上,手动构造请求触发bug,探索定位此类问题的通用思路。
如何确定bug可以导致CPU飙升?为何会引发OOM?
1) 在Java服务上开启JMX,在本地使用来查看Java服务在运行过程中的内存、GC、线程等信息。VisualVM是Sun的一个OpenJDK项目,它是集成了多个JDK命令工具的一个可视化工具,它主要用来监控JVM的运行情况,可以用它来查看和浏览Heap Dump、Thread Dump、内存对象实例情况、GC执行情况、CPU消耗以及类的装载情况,也可以使用它来创建必要信息的日志。
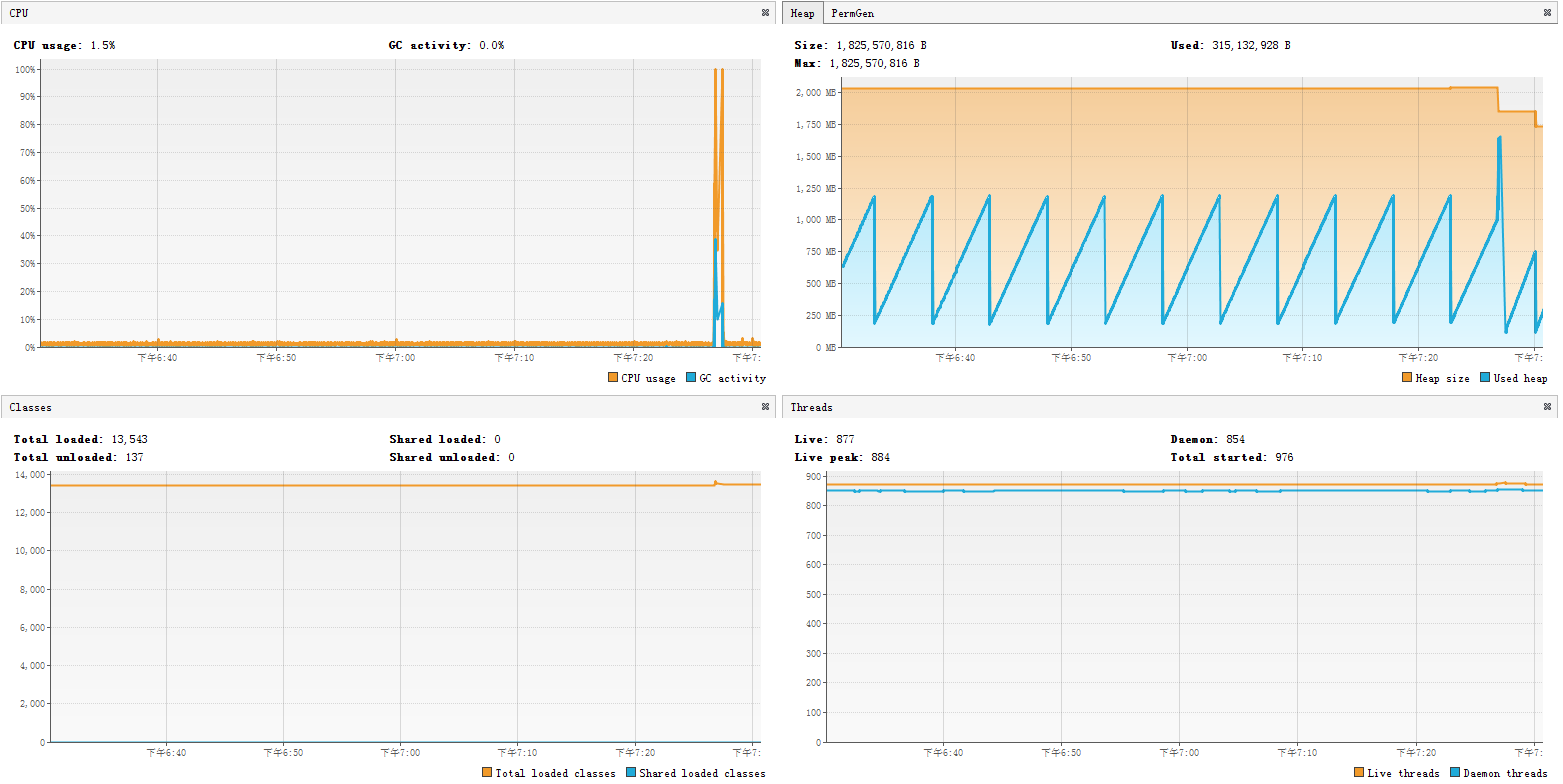
可以看到逻辑被命中的时候,CPU确实是升到100%的,此时也发生了Full GC告警。尝试着多发了几次请求,服务直接就挂掉了。这里有个问题是:不是已经Full GC了吗,为什么还会发生OOM?实际上,虽然JVM已经开始回收内存,但是由于对象被引用,这些内存是回收不掉的。从GC日志可以看到回收的情况:
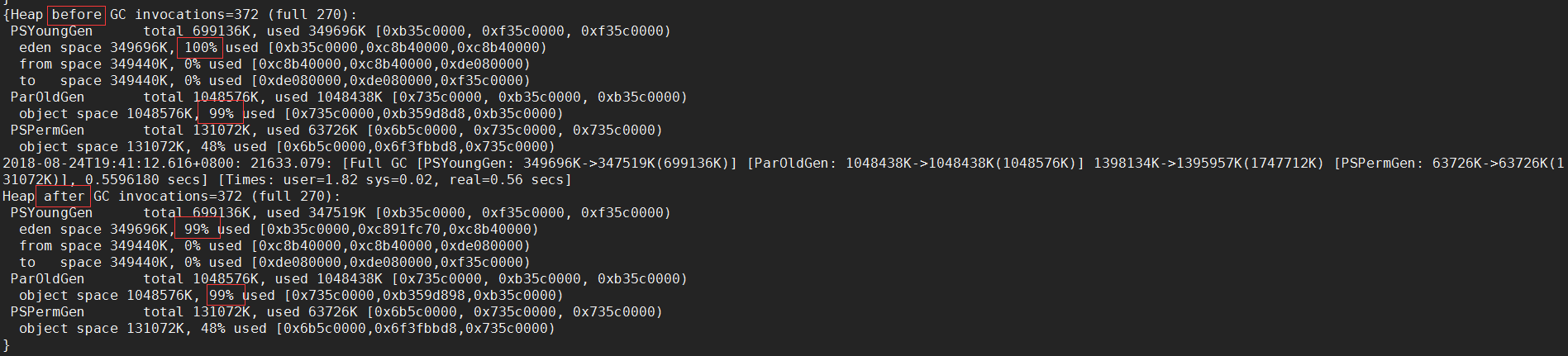
从GC日志中可以看到,新生代的Eden区域与老年代都已经被占满。如果新生代放不下对象的时候,object会直接被放到老年代中。除了GC日志,也可以使用jstat命令来堆Java堆内存的使用情况进行统计展示:
jstat -gcutil 12309 1000 10
1000为统计的间隔,单位为毫秒,10为统计的次数,输出如下:
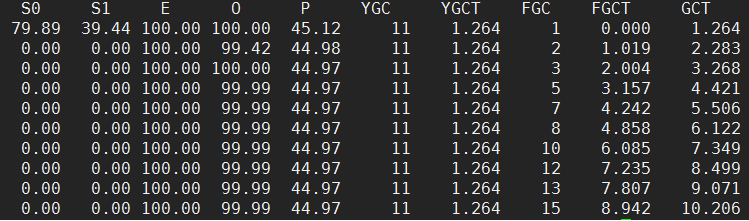
从输出中同样可以看到E(Eden)区与O(Old)区都已经被占满了。其他几个输出项的含义如下:
- YGC: 从启动到采样时Young Generation GC的次数
- YGCT: 从启动到采样时Young Generation GC所用的时间 (s).
- FGC: 从启动到采样时Old Generation GC的次数.
- FGCT: 从启动到采样时Old Generation GC所用的时间 (s).
- GCT: 从启动到采样时GC所用的总时间 (s).
可以看到JVM一直在尝试回收老年代,但是一直没能将内存回收回来。
如何获取占用CPU最高的线程id?
2)可以登上机器,确认下是什么线程使CPU飙高。先ps查看Java进程的PID:

拿到进程pid后,可以使用top命令,来看是什么线程占用了CPU。
top -p 12309 -H
-p用于指定进程,-H用于获取每个线程的信息,从top输出的内容,可以看到有四个线程占用了非常高的CPU:
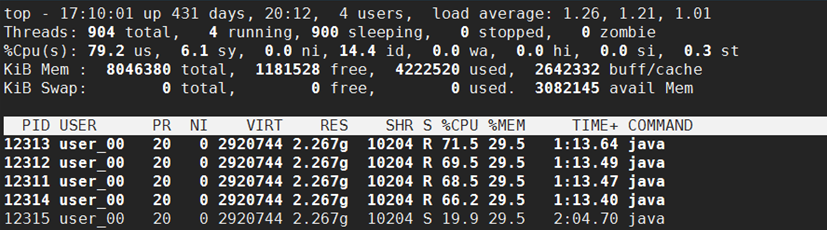
到这里可以拿到12313、12312、12311、12314这四个线程id。为了确定这些是什么线程,需要使用jstack命令来查看这几个是什么线程。
高占用CPU的是什么线程?
3) jstack是java虚拟机自带的一种堆栈跟踪工具,用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息。使用下面命令,将java进程的堆栈信息打印到文件中:
jstack -l 12309 > stack.log
在线程堆栈信息中,线程id是使用十六进制来表示的。将上面四个四个线程id转换为16进制,分别是0X3019、0X3018、0x3017、0x301A。在stack.log中可以找到这几个线程:
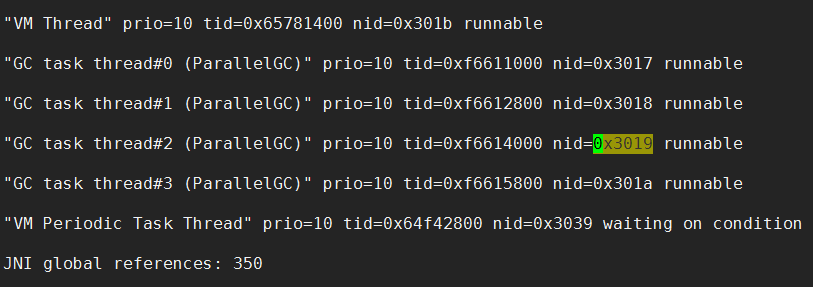
到这里可以确定的是,死循环引发了Full GC,四个GC线程一直尝试着回收内存,这四个线程将CPU占满。
是哪些对象占用了内存?
4)Full GC、OOM、CPU被占满的问题都得到了解答。那么再次遇到类似的线上问题时,如何确定或者缩小问题范围,找到导致问题的代码呢?这时候需要进一步观察的是Java堆内存的信息,查看是什么对象占用了内存。可以使用上文提到的VisualVM来生成headdump文件:
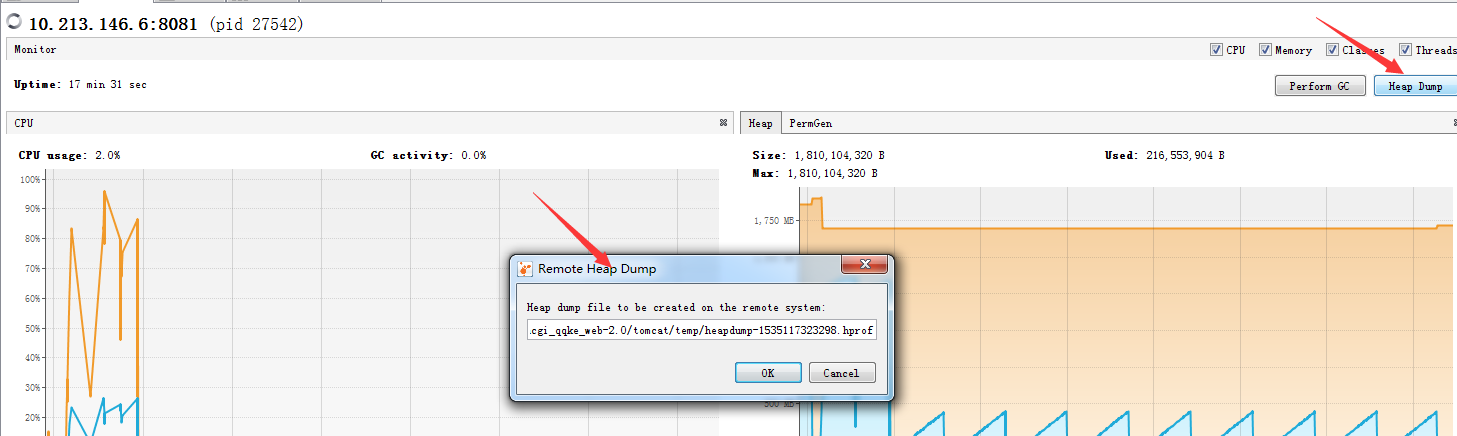
也可以在机器上使用jmap命令来生成head dump文件。
jmap -dump:live,format=b,file=headInfo.hprof 12309
live这个参数表示我们需要抓取的是目前在生命周期内的内存对象,也就是说GC收不走的对象,在这种场景下,我们需要的就是这些内存的信息。生成了hprof文件后,可以拉回到本地,使用VisualVM来打开它进行分析。打开后可以看到:
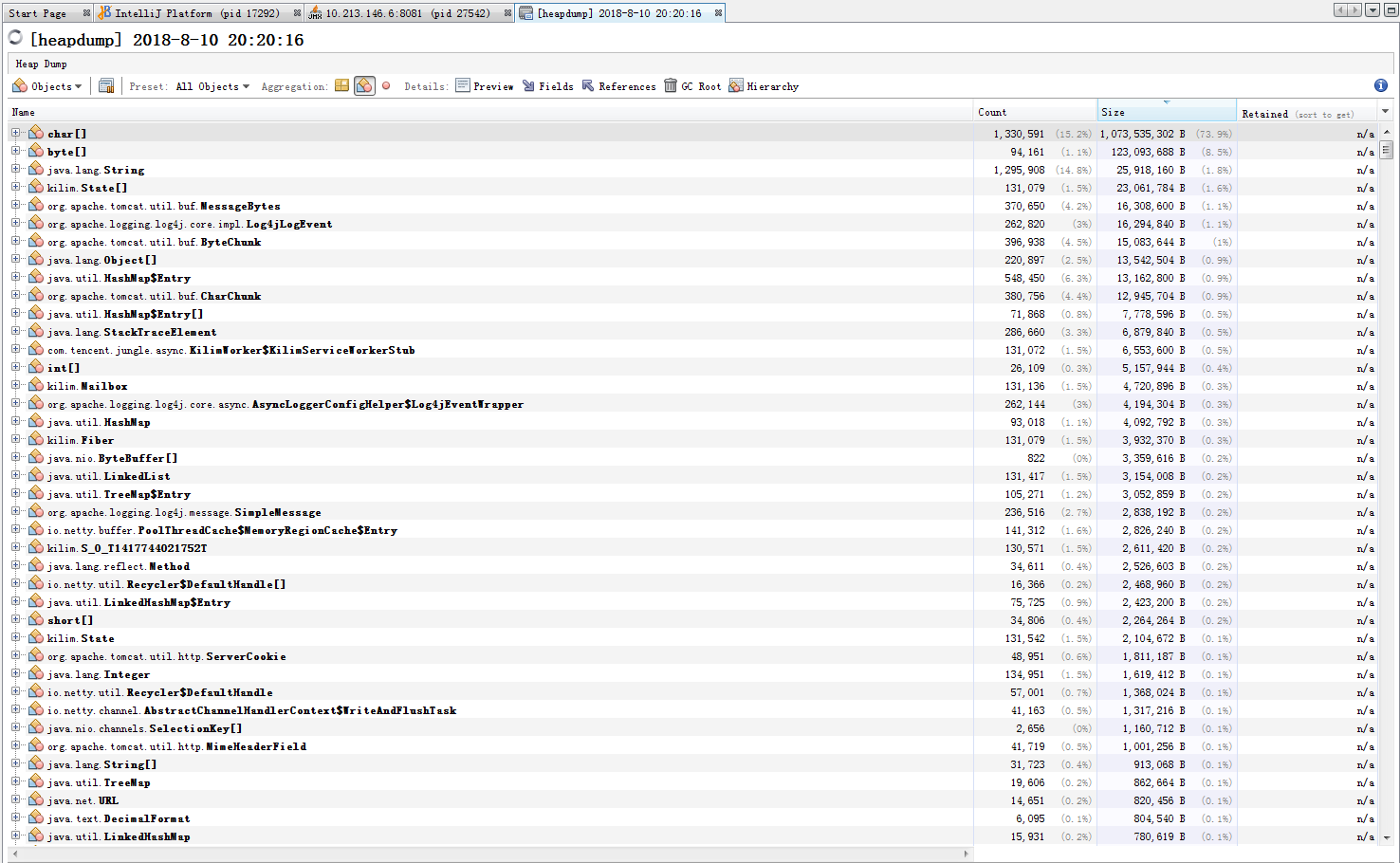
从信息中可以看到,字符串char[]在占了内存的73%,因此可以确定的是内存泄漏与字符串有关。通常生成的headdump文件会很大,也可以使用下面的命令,来查看占用内存最多的类型:
jmap -histo 12309 > heap.log
输出内容如下:
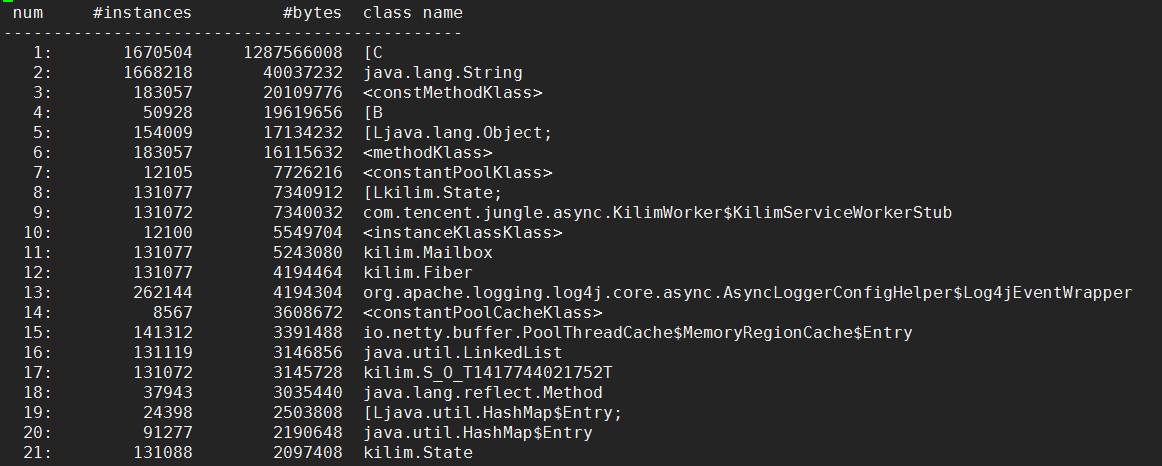
能否对堆内对象进行查询?
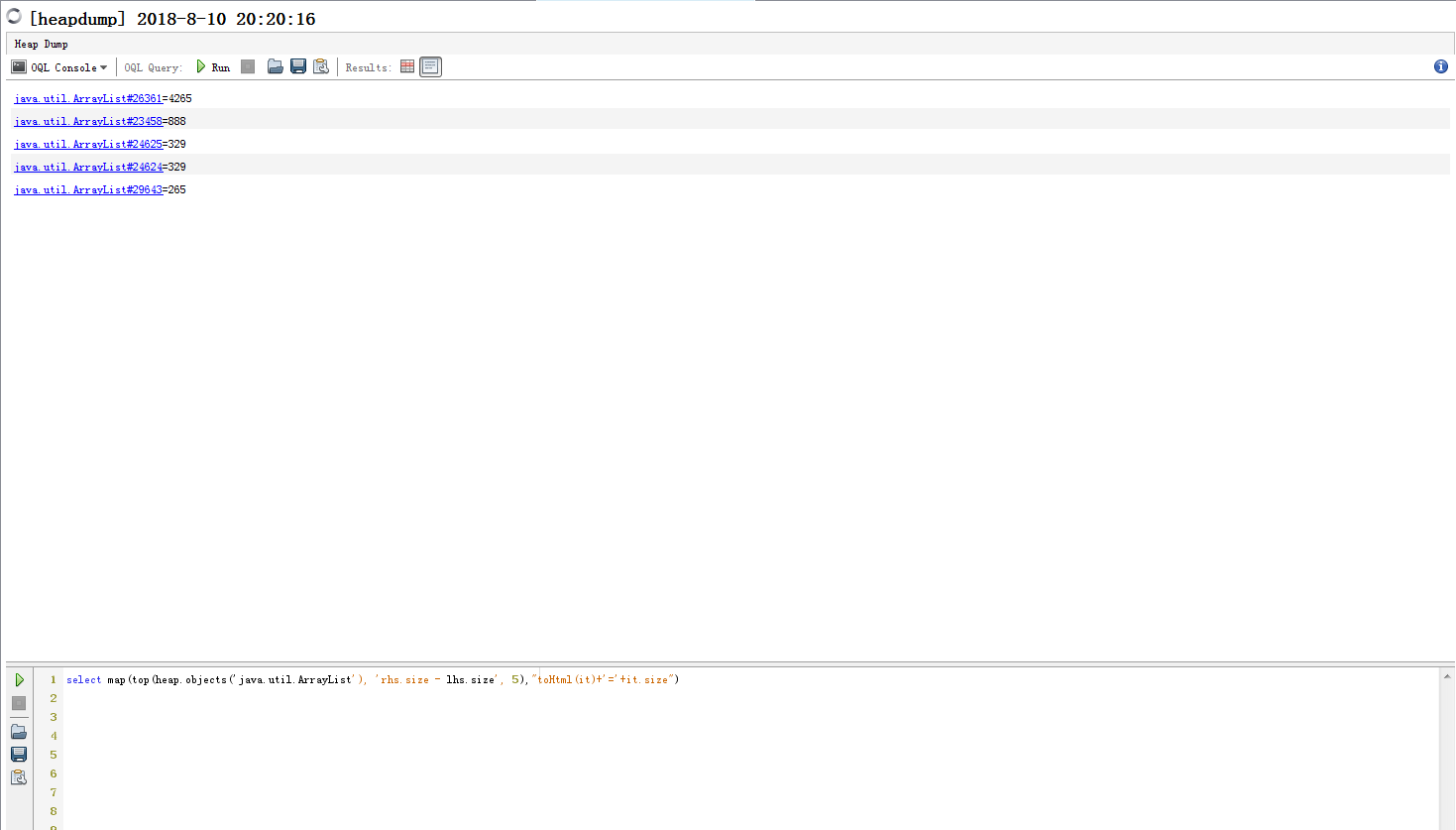
5) 到这里突然有个想法,如果能够分析出相似度高的字符串,那么有比较大的可能是这些字符串存在泄漏,从而可以缩小问题代码的范围。确实是有这么一种工具来对堆内的对象进行分析,也就是OQL(Object Query Language),在VisualVM中可以对headdump文件执行对象查询,下面是一个示例,查找包含内容最多的List:
select map(top(heap.objects('java.util.ArrayList'), 'rhs.size - lhs.size', 5),"toHtml(it)+'='+it.size")
查询结果如下:
如何查找到相似度最高的字符串,还在继续学习研究中。
一些疑问与总结
1)为什么无法抓到引发Full GC的线程?一个猜测是线程抛出OOM异常之后就被终止了,线程只存活了很短的时间。
2)为什么对Eden区回收后存活的对象,不会被拷贝到survivor区?从上面的GC日志可以看到,BeforeGC 与 AfterGC,新生代中的两个survivor区(也就是from\to)一直都是0%,这里猜想可能是survivor区太小,没有足够的空间存放从Eden区拷贝拷贝过来的对象。同时老年代也没有足够的空间(已经99%了),因此JVM的GC基本没有什么有效的回收操作。 3)重现问题时,在日志里发现了一个OOM的错误信息:java.lang.OutOfMemoryError: GC overhead limit exceeded
这种情况发生的原因是, 程序基本上耗尽了所有的可用内存, GC也清理不了。JVM执行垃圾收集的时间比例太大, 有效的运算量太小. 默认情况下, 如果GC花费的时间超过 98%, 并且GC回收的内存少于 2%, JVM就会抛出这个错误。从这里也可以看到GC线程一直在尝试回收内存,但是回收效果实在太差,也就是第二点提到的。
4)当时在线上环境出现问题时,看到很多log4j的错误日志信息,是什么原因?猜测大概是写日志的I/O操作要经过内存,而内存已经被使用光,无法进行写操作所导致。这些问题都可以进一步研究。对于一般的OOM问题,通过这几个方面的思考,大致可以锁定问题所在,或是缩小问题可能发生的范围。例如对某些特定类型的内存泄漏来说,到这一步已经可以分析出是什么类型导致内存泄漏。而对本案例来说,根据排查结果可以优先考虑的是字符串的泄露,代码review中查看是否有操作字符串的地方,而不会将问题的优先级锁定在打包问题上。
(完)